Introduction
This blog article is one of a series that we are putting together to compare Amazon Web Services and Google Cloud Platform. At Priocept we use both platforms extensively, and each has relative strengths and weaknesses. In this article we compare how each platform implements metadata and start-up and shutdown events for virtual machines (compute instances).
Both AWS EC2 and Google Compute Engine support the concept of instance metadata. This is data that is associated with a specific virtual machine instance, which can be used to describe that instance. Both platforms also allow metadata to be used to control the start-up behaviour of an instance. But when you look into the details, the Amazon and Google implementations are quite different.
EC2 Metadata Implementation
AWS provides metadata functionality for its EC2 instances, but the metadata that is available mostly describes inherent properties of the instance, and cannot be used to store arbitrary information. The following output from the ec2-metadata command line tool shows the metadata that is available:
$ ec2-metadata --help Usage: ec2-metadata Options: --all Show all metadata information for this host (also default). -a/--ami-id The AMI ID used to launch this instance -l/--ami-launch-index The index of this instance in the reservation (per AMI). -m/--ami-manifest-path The manifest path of the AMI with which the instance was launched. -n/--ancestor-ami-ids The AMI IDs of any instances that were rebundled to create this AMI. -b/--block-device-mapping Defines native device names to use when exposing virtual devices. -i/--instance-id The ID of this instance -t/--instance-type The type of instance to launch. For more information, see Instance Types. -h/--local-hostname The local hostname of the instance. -o/--local-ipv4 Public IP address if launched with direct addressing; private IP address if launched with public addressing. -k/--kernel-id The ID of the kernel launched with this instance, if applicable. -z/--availability-zone The availability zone in which the instance launched. Same as placement -c/--product-codes Product codes associated with this instance. -p/--public-hostname The public hostname of the instance. -v/--public-ipv4 NATted public IP Address -u/--public-keys Public keys. Only available if supplied at instance launch time -r/--ramdisk-id The ID of the RAM disk launched with this instance, if applicable. -e/--reservation-id ID of the reservation. -s/--security-groups Names of the security groups the instance is launched in. Only available if supplied at instance launch time -d/--user-data User-supplied data.Only available if supplied at instance launch time.
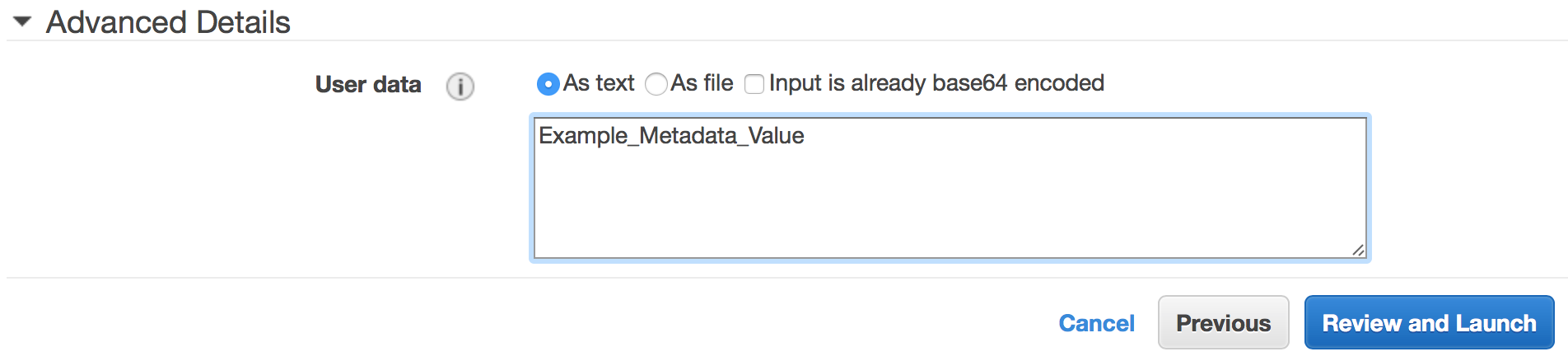
Of the list of metadata fields that are supported, only one is available for storing arbitrary metadata – the user-data field. This field can hold up to 16KB of text and can be used in a variety of ways as described in more detail below. The user-data metadata value can be set via the AWS web console at instance creation time, as shown in the screenshot below. Alternatively, it can be set via the AWS command line interface (CLI), or via CloudFormation if your EC2 instances are defined using an infrastructure-as-code approach.
Google Compute Engine Metadata Implementation
The Google Compute Engine (GCE) metadata implementation is quite different to EC2, and also more powerful. The most obvious difference is that GCE allows the definition of any arbitrary number of metadata fields, with any field names and values of your choosing.
Since EC2 only provides the single user-data metadata field, if you want to store more than once piece of metadata information against an instance, you either need to use this single field to store multiple values using a format of your choice (name=value& query string style, name:value config file style, etc.), or you need to store the data somewhere else (see below).
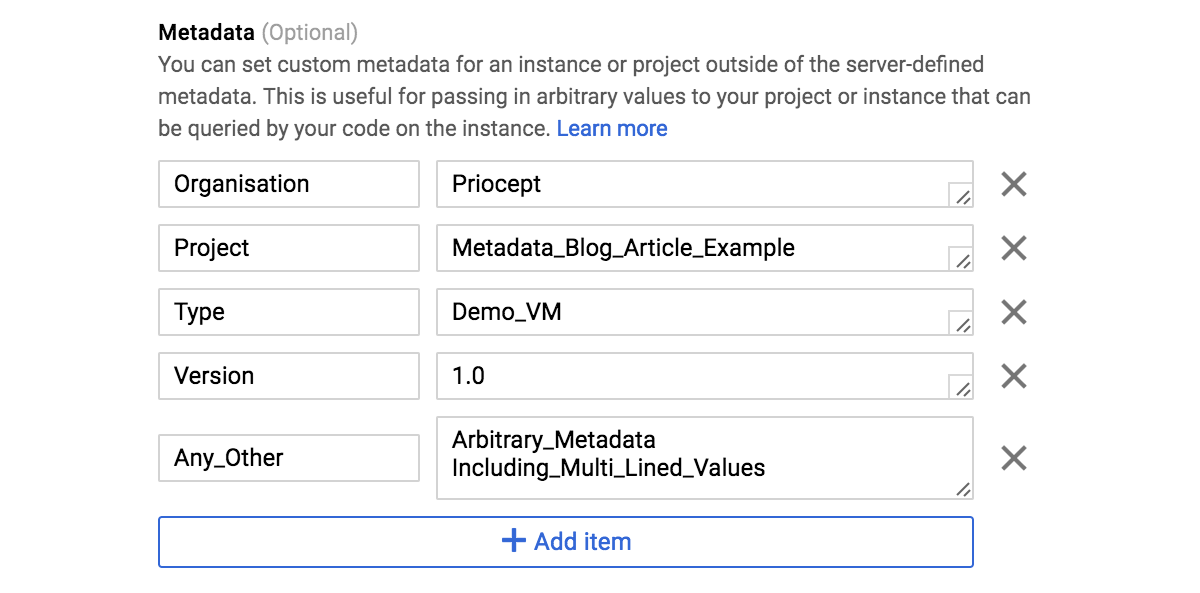
In contrast, you can neatly structure GCE metadata as multiple fields that hold multiple or unrelated values.
As with EC2, GCE metadata can be defined either in the web console as shown in the screenshot below, or via the CLI, or using Deployment Manager (Google’s equivalent of CloudFormation).
One very common use of multiple metadata values on Priocept projects is to configure the bootstrapping process of configuration management tools such as Ansible or Puppet. If you are using these tools to auto-configure a new instance, then they need instructions on where to fetch the configuration, and what type of instance should be figured.
Metadata is the obvious place to define this information with a hierarchical structure such as Organisation/Project/Type that uniquely defines the configuration that the instance should be created with. With GCE we can neatly store this metadata in three individually editable fields, but with EC2 we either need to shoehorn it all into the single user-data field, or we need to store it somewhere else.
Metadata Retrieval
Once you have defined the metadata, you will most likely have some kind of process inside the instance that will need to retrieve it. EC2 and GCE both provide access to the metadata from inside the instance, using a simple HTTP interface.
For EC2 this is as follows:
http://169.254.169.254/latest/user-data
And for GCE it looks like this:
http://metadata/computeMetadata/v1/instance/attributes/<metadata_name>
It’s not clear why Amazon decided to publicly document an IP address for this interface rather than using a hostname– but let’s hope they don’t need to change it any time soon (IPv6?) as this will break a lot of code!
Note that on EC2 (Amazon Linux), the user-data metadata is also available at the following file location:
/var/lib/cloud/instance/user-data.txt
But if this file is edited, the change will not be reflected in the web console. The HTTP interface described above is the officially supported method of retrieving the metadata.
Metadata Based Start-up and Shutdown Control
EC2 and GCE differ in their implementation of instance control via metadata. Looking at GCE first, this supports separate metadata for both start-up and shutdown scripts. The start-up and shutdown scripts are implemented in the form of specially named metadata (startup-script and shutdown-script), but are presented separately in the web console, as shown in the following screenshot:
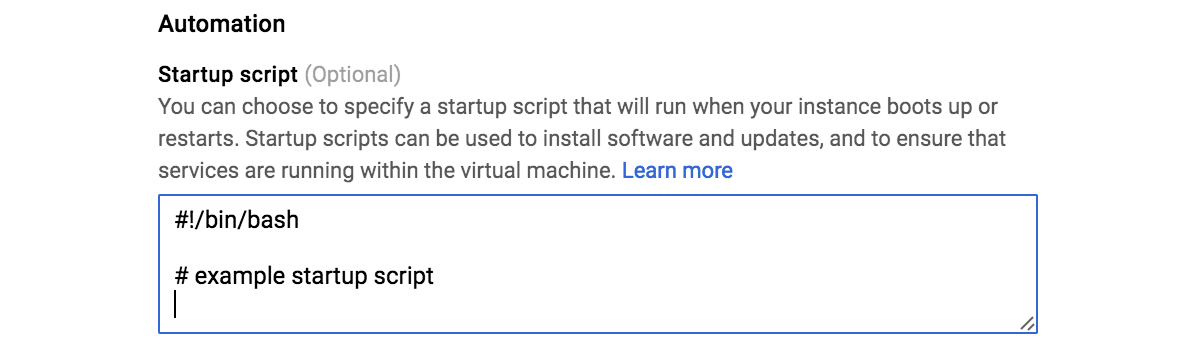
So the concepts of instance metadata versus start-up/shutdown control are fairly well isolated.
In comparison, EC2 has no separate configuration fields for start-up or shutdown control. Instead, the content of user-data field is executed if it is in a valid format (shell script on Unix or PowerShell on Windows). So the user-data field potentially ends up serving more than one purpose, and can end up containing both executable code (which is usually generic and common across many instances), and configuration metadata (which is usually instance specific).
In practice, the GCE approach makes for a much cleaner implementation of instance configuration and bootstrapping.
It is also worth noting that EC2 does not provide a shutdown script feature, and this must be implemented manually. It does, however support cloud-init formatted user-data, which would require manual configuration on GCE.
Finally, an important difference between EC2 user-data and GCE start-up scripts is that the former only runs once, on initial creation of the instance, whereas GCE start-up scripts run on every boot. This means that on EC2 you will need to manually implement a mechanism for running new code on each boot, if required, and conversely, on GCE you may need to implement a process to stop your start-up script from running on subsequent reboots if it is intended to perform a one-off task such, as installation and configuration management tasks.
Note that while the implementation of metadata fields is an inherent function of the EC2 or GCE platform, the implementation of how these fields are interpreted or used during start-up, is an implementation of the instance itself and depends on the image that your instances are built from. The above behaviour describes how the Amazon Linux and Google CentOS (or Debian) images behave, but if necessary you can create your own custom image templates, which use the metadata differently.
Metadata Size Limits
It’s worth noting that while EC2 has a size limit of 16KB on its user-data field, GCE has a limit of 32KB. The 16KB limit is quite easy to come up against if you have a complex start-up script, in which case your user-data script will need to contain simple wrapper code which fetches the full script from somewhere else (e.g. from an S3 bucket or from GitHub) and then execute it. The 32KB limit on GCE is usually enough to store even the most complex start-up scripts directly against the instance, but it would be nice if the limit was larger still so that it was never a consideration.
Cross-Instance Metadata
In addition to instance-specific metadata in GCE, Google Cloud Platform also supports the concept of project-wide metadata. A project in Google Cloud Platform is an isolating entity under which any number of GCE instances or other resources can be created.
Creating metadata at the project level means that duplication of metadata can be avoided where it is common to multiple GCE instances. A project-wide piece of information such as the name of your system can be stored as once piece of metadata at the project level, and then accessed by all GCE instances in the usual way (via the HTTP interface described above), rather than having to repeat the metadata definition for each instance.
AWS does not provide an equivalent feature, presumably because it does not have the concept of projects as a containing entity for its resources.
Tags and Labels
In addition to metadata, AWS and GCP support the concepts of “tags” and “labels” respectively.
AWS uses the “tags” terminology and these are described by Amazon as “metadata assigned to an instance or other EC2 resource”. So at first glance they appear to be a direct equivalent to the metadata features of GCP described above, but in practice present a couple of issues if used in this way.
Firstly, AWS tags are not accessible via the HTTP interface described above, so if you want to retrieve tag values from inside an instance to control its behaviour, you will need a rather more complex (CLI-based) implementation
Secondly, retrieval of tag values from within an EC2 instance requires that the EC2 instance is assigned an AWS IAM role which grants it access to the tags – access is not granted by default.
The techniques for overcoming these two issues are described in our accompanying article AWS Tag Retrieval from Within an EC2 Instance.
Google Cloud Platform has the concept of “labels” which are equivalent to AWS tags. However, since GCE has a fully featured metadata implementation, there should be no need to use labels to store metadata against an instance. This allows a clean separation where labels are used only for housekeeping and administrative organisation of instances, while metadata can be used to control the behaviour and internal configuration of an instance.
To add further confusion, Google Cloud Platform also has the concept of “tags” in addition to “labels”, but these are used only in relation to managing networking and firewall rules and are not covered here.
Summary
Once you start looking into the details, Amazon EC2 and Google Compute Engine are surprisingly different in their implementations of instance metadata.
Google provides several very useful features that are not available on EC2, specifically the ability to define and retrieve any arbitrary number of metadata values, the ability to define project-wide metadata, and the ability to keep the concepts of instance metadata and instance startup/shutdown control completely separate from one other. Meanwhile, EC2 requires the use of tags as a form of metadata, which in turn needs some fancy CLI and shell script work to retrieve the tag values from inside an instance.
In a future blog article, we will look at how instance metadata can be used to control your configuration management bootstrapping process.