Summary
The Google Search Appliance (or GSA) is a rack-mounted content indexing device. Based on Google search technology, the device is the company’s consumer-facing search solution. As the device develops market share, an increasing number of CMS products are advertising inbuilt search integration as a feature. Here, we provide details about the GSA, its usage, and relevant capabilities and limitations.
Google Search Appliance – Overview
The GSA sits above the Google Mini as the flagship hardware search product offered by Google, currently capable of indexing up to 10m documents (GB-7007 model) and 30m documents (GB-9009 model) compared to 300,000 documents on the Google Mini.
The product is offered as a rack-mount hardware device, using an Intel processor on Dell hardware. Google claims that offering a hardware solution removes the need for skilled administrators or timely hardware/software upgrade issues. The GSA FAQ states:
rest assured that the Google Search Appliance can easily scale to meet the document capacity and query volume in your organization.
The GSA is sold as a “single easy-to-use search box”, with much emphasis on the ability of a business to easily integrate the device with existing systems and begin indexing and serving search results immediately. Along with ease-of-use, Google claims that the GSA offers:
- Dynamic Scalability – Scale to thousands, millions, even billions of documents – all without disrupting existing GSAs
- GSA-to-GSA Unification – Link multiple GSAs, separated across departments or geographies to provide a unified set of results
- Fine tune relevancy
- Customizable security
- Social search features – including ‘User Added Results’
- User-centric innovations – such as Query Suggestions
Priocept was recently engaged by one of its clients, a well-known insurance market, to help implement a new search facility for part of its corporate website using the Google Search Appliance. The project involved the set-up and configuration of the GSA, along with migration of documents and metadata from the existing part of the website to a new structure, thus enabling users to search more effectively; the more advanced features of the GSA were used in order to provide an enhanced search experience for users.
Content Gathering
The GSA offers two approaches to content discovery: crawling, and feeds.
Crawling
Using the default administration interface, the GSA is provided with entry (starting) points to a repository of content; usually web-accessible, but less commonly, a file-based or database repository.
Along with starting points (in the case of web content, URLs), an administrator will specify:
- Crawl depth – how many pages beyond the original starting page to crawl. Typically, this would be set to ‘unlimited’, combined with a host restriction.
- Host restriction – specify a domain or network location to crawl within, typically ‘all pages on the MySite.com domain’.
- File location patterns – we can tell the crawler to whitelist or blacklist content found in certain locations.
- File types or extensions – the crawler can be instructed to whitelist or blacklist content with given extension or MIME types.
- Destination collection –specifying a collection (index subset) for all crawled results to be placed in.
In addition to the above configuration points, the start time and repetition frequency of a crawl can be specified. A typical usage of this feature would be to begin crawling at a time when server usage is low, and to repeat that scheduled crawl every 24 hours. This is a distinct alternative to ‘continuous crawls’, where the GSA endlessly crawls for new and updated content.
Feeds
The GSA allows an administrator to submit an XML file which contains explicit details of URLs (or file locations) to be crawled. The feature is provided to give administrators greater control of which content is indexed, at what time, and in what order.
The default XML structure for a URL entry to be processed by the GSA is shown below:
<record url="http://www.mysite.com/content/singlepage.html" mimetype="text/html"> </record>
XML entries can be submitted one at a time, or in a batch. The GSA then processes each URL in turn, indexing the content in the normal way and adding the result to a specified collection.
Adding Metadata to Content
The GSA builds a full-text index of every document it encounters. When searching, emphasis is placed on document titles; however, in the case of HTML content, the GSA ignores most tags usually associated with search engine content discovery (‘Description’ and ‘Keyword’ metatags included).
Instead, the GSA allows full control over submitting metadata through the feed content discovery method.
All metadata is stored as string values, attached to a particular URL. Submitted as an XML feed entry, this would appear as below:
<record url="http://www.mysite.com/content/singlepage.html" mimetype="text/html"> <metadata> <meta content="Accounts" /> <meta content="Bob Jones" /> <meta content="01-01-2010" /> </metadata> </record>
Restrictions on acceptable metadata largely surround ‘invalid’ characters (typically, non standard alphanumeric characters), and metadata must also conform to acceptable XML characters.
Integrating GSA with a Content Management System
The following diagram illustrates how content can be generated within a CMS, with the metadata stored separate to the document. A broker between content and the GSA can gather the two essential items (a URL, and any metadata associated with that URL, and form the necessary XML for a GSA feed item.
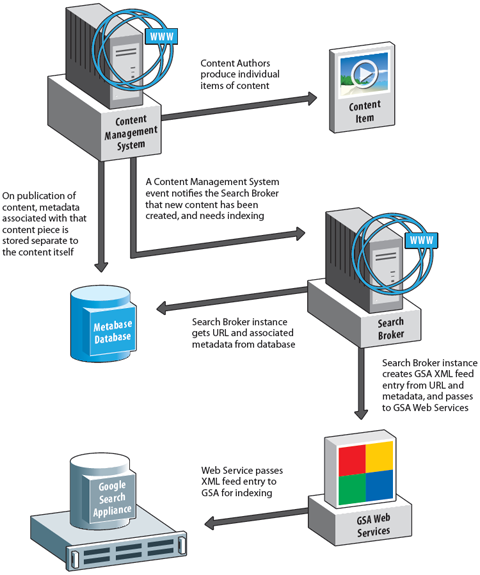
Creating Search Pages
The GSA provides standard, Google branded search pages as standard. As such, a business implementing a GSA device is not obliged to develop separate pages to handle searching.
However, in most cases, a business will want to create specific branded search pages. The interface for submitting search queries to the GSA, and the return of results, is built to accommodate this need easily.
Searching from a Custom Page
Search queries follow the ‘Google search protocol’, which is a standard HTTP GET request. The request is a URL, which specifies:
- The location of the GSA device
- The port which is listening for incoming requests
- The query itself, which combines keywords, along with any additional metadata a user wishes to filter results by.
A typical search query URL would look as follows:
http://search.mycompany.com/search? q=query+string&site=default_collection&client=default_frontend&output=xml_no_dtd&proxystylesheet=default_frontend
Displaying Returned Results
Results are returned from the GSA in either XML or HTML format. In most cases, a client will wish to return the results in XML format, for ease of styling in line with existing branding.
While documentation of the results format is outside of the scope of this document, the structure can be summarized as follows:
- Details of the character encoding used, any caching passed through
- An element encapsulating all search results returned
- A quantity of (a) all search results found and (b) number of search results returned in this specific result set (results are returned in groups of 10, 20, 50, 100, etc)
- Individual results.
Google supplies several XSLT sheets which can be used as starting points to model the XML search results into browser-friendly HTML.
Many web frameworks provide controls to take an XML input, apply an XSL transformation to that XML, and display the results on-page.
Searching for Metadata
If we revisit the basic URL structure for a GSA query,
http://search.mycompany.com/search?q=hello+world
we can see that the only search query so far is for an occurence of the strings ‘hello’ and ‘world’ in a document. If metadata is associated with a particular URL in the GSA index, it is possible to filter results based on those metadata values.
Based on a feed entry structure such as:
<record url="http://www.mysite.com/content/singlepage.html" mimetype="text/html"> <metadata> <meta content="Accounts" /> <meta content="Bob Jones" /> <meta content="01-01-2010" /> </metadata> </record>
we could search for the terms ‘hello’ and ‘world’, but restrict the search only where the document contains a document_category of ‘Human Resources’, with a search query such as:
http://search.mycompany.com/search? q=hello+world&inmeta:document_category:Human+Resources
The GSA provides functions and a syntax mechanism to treat metadata as data types other than a basic string.
To repeat the ‘hello world’ search (above), however, restrict documents to those expiring between December 2009 and February 2010, we could construct a query such as:
http://search.mycompany.com/search? q=hello+world&inmeta:document_date_of_expiry daterange:2009-12-01..2010-02-01
Finally, combining the ‘Hello World’ keyword search, a document_category filter, and a document_date_of_expiry filter, we would have a query such as:
http://search.mycompany.com/search? q=hello+world&inmeta:document_category:Human+Resources &inmeta:document_date_of_expiry:daterange:2009-12-01..2010-02-01
Administration
The HTTP based GSA Administration panel allows configuration and service stop/start of all appliance operations.
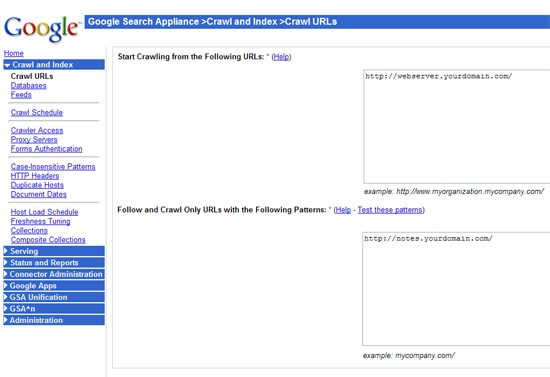
In addition to configuration, the administration area is also the entry point for viewing statistics and reports relating to search activity, crawl success/failures, crawl status, and general server health.
Quirks and Potential Problems
Non-standard characters
The GSA, while processing new search item feeds, will skip content where any ‘invalid’ character appears in the metadata. There is no official list of invalid characters, and the GSA does not log the reason why a particular feed entry was rejected.
Feed Reporting
When entering a batch of search feed items, the GSA will only display success/failure results for the last five feed items processed. It may be typical to index thousands of documents in one batch, and as such, determining the overall success or failure of a batch feed insert is currently impossible.
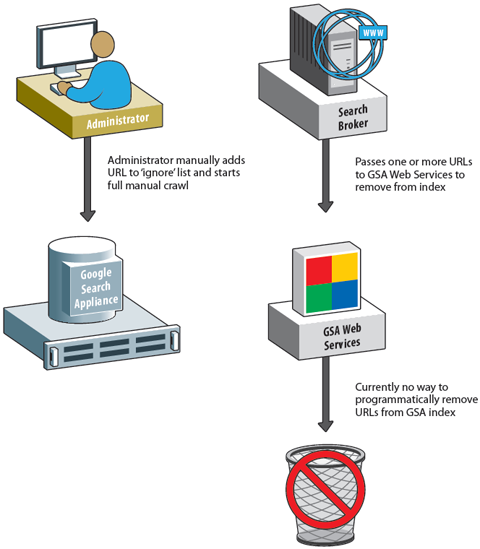
Removal of Items from GSA Index
Currently, removal of an item from the GSA index is manual, and non-intuitive. To remove a single item from the index, an administrator has to manually add that item URL to a global ‘ignore’ list in the GSA administration panel, and start a fresh full crawl of content. Only when the next crawl has completed will the document be absent from search results. For batch operations, this can result in a major administrative effort.
Ampersand Usage
Due to GSA queries being URL based, the ampersand (‘&’) character is reserved and cannot be used in keyword searches. Care must be taken to URL-encode this character.
Large Number of Results
Search results include an overall number of matches found, for display purposes (commonly, ‘Results 1-10 of 1234’). If a search returns more than 1000 results, total result numbers are estimated.
Maximum Search Terms
The GSA imposes a limit of 50 search terms. Any additional search terms are ignored by the GSA.
Stopping a Running Feed Batch
Once a batch of XML feeds has been sent to GSA for indexing, the batch cannot be interrupted. This can cause problems if an erroneous batch has been started, as, depending on batch size, the process can take hours or days.
2.5mb / 30mb File Size Limit
The GSA will ignore any content in a file beyond the first 2.5mb processed. Any files larger than 30mb will not be processed by the GSA at all.
Summary
The GSA lives up to its claims to be extremely easy to set up and administer. Once all hardware installation considerations have been met, the device is available to administer through a web-browser, and with adequate network visibility, is able to begin indexing content immediately. Pre-installed search ‘front ends’ are available meaning no extra development work is required to begin serving search requests as soon as content is indexed.
The Google-provided documentation is thorough and accurate, and supplemented by a regularly maintained developer support network (specifically, Google Groups).
Although very powerful in many areas, there are some drawbacks with the GSA, particularly relating to index management: removal of items from the GSA index is an elaborate and manual process, and will not suit some scenarios; furthermore, once a batch feed has been started, there is no way to interrupt or pause this import.
All-in-all, for standard document or page-centric indexing and search requirements in the enterprise, the Google Search Appliance performs very effectively, although more unusual uses may require customisation or addition of extra functionality to achieve the desired results, particularly around administration.
Thanks to Chris Perks for his input.