Introduction
Google Cloud Platform (GCP) provides a comprehensive range of different load balancing solutions, but the learning curve can be steep and it can be difficult to identify the most appropriate load balancing solution to use. Further adding to the challenge, if you are using Deployment Manager (GCP’s equivalent of AWS CloudFormation) to define your load balancing using infrastructure-as-code, you may find the documentation difficult to follow and difficult to translate into a working solution. In this article we will provide an overview of how to implement Network Load Balancing on GCP, using Deployment Manager infrastructure-as-code.
GCP Load Balancing Options
At a high level, GCP provides three main types of load balancing solutions:
- Network Load Balancing – this provides layer 4 load balancing that can deal with any kind of TCP/UDP traffic.
- HTTP(S) Load Balancing – this provides layer 7 load balancing and operates on HTTP/HTTPS traffic.
- Internal Load Balancing – this is equivalent to Network Load Balancing, but can be used for balancing internal infrastructure, that is not visible to the public internet.
More advanced forms of “global” load balancing are also provided (SSL and TCP Proxy load balancing) for globally distributed systems, but are not covered here.
Note that you may need to implement load balancing even if you only have a single server (Compute Engine) instance behind the load balancer, but have that instance within an instance group (the GCP equivalent of an AWS Auto Scaling Group), so that the instance is “self-healing” and is automatically replaced by a new instance if it fails. In this configuration, a load-balancer is used in front of the instance group, to present a consistent address or hostname through which the server can be accessed, when the instance is terminated and relaunched.
In this article we will focus on implementation of Network Load Balancing. This is the solution that you will use for any non-HTTP based traffic, and may also use for HTTP/HTTPS traffic if you do not need the advanced features of layer 7 load balancing.
Network Load Balancing Components
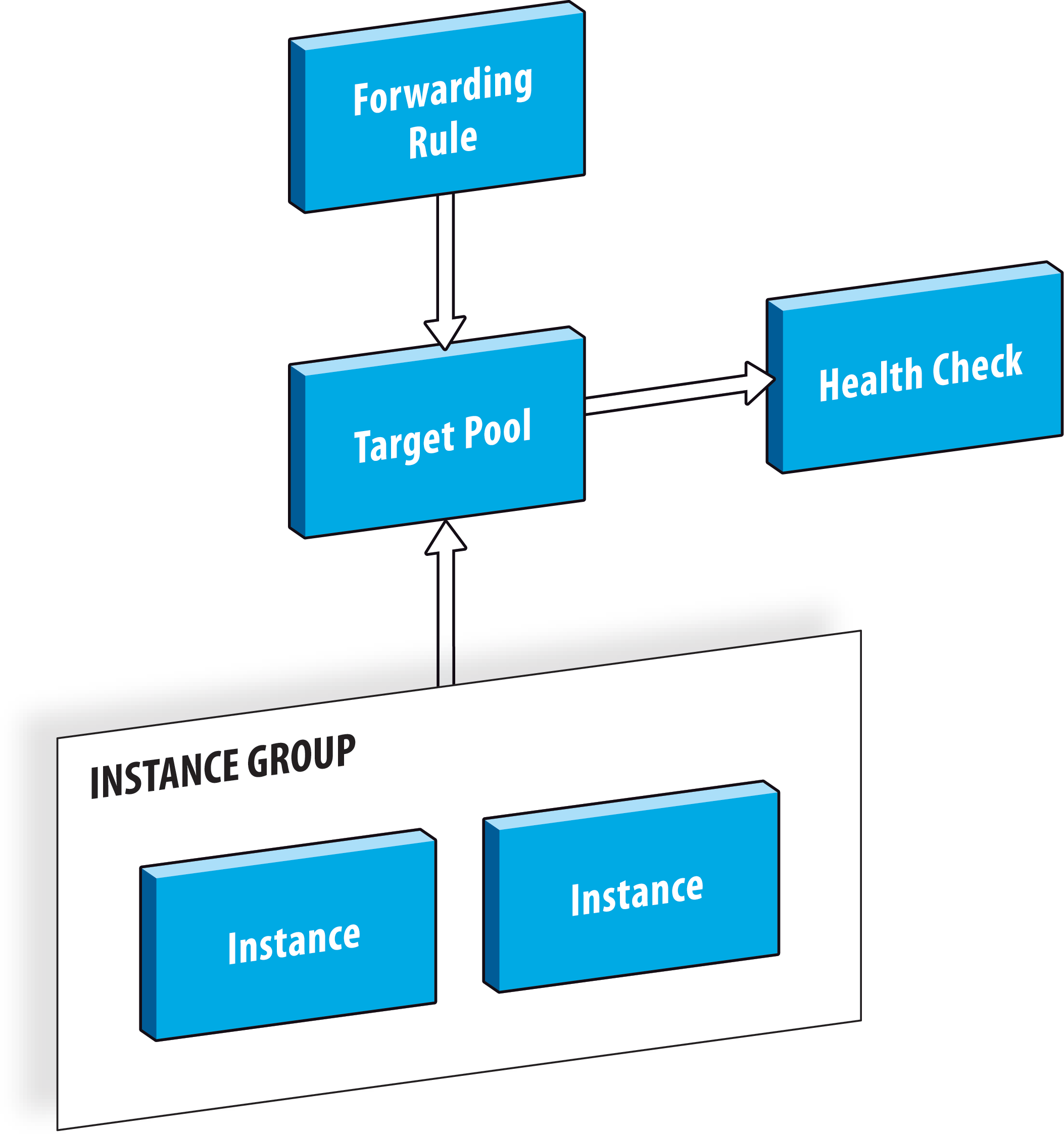
Network Load Balancing on GCP is implemented in the form of three different components. Each component is a different type of GCP “resource”:
- Target Pool – this defines the pool of Compute Engine instances that the load balancer will route requests to. A target pool can also include a reference to a health check definition (below), which is used to indicate which instances are healthy and should have requests routed to them, and which instances are unhealthy and should not serve any requests.
- Forwarding Rule – this defines the externally facing interface of the load balancer, including the protocol, IP address and port. The IP address will be a public address, either ephemeral or static.
- Health Check – a health check can be optionally defined, and is referenced by the target pool as described above.
If we are using Deployment Manager to create these resources using infrastructure-as-code, then the resource types that we need to create are compute.v1.targetPool, compute.v1.forwardingRule and compute.v1.httpHealthCheck. Note that there are other types of health check besides the HTTP health check, but only the HTTP health check type is supported for use in combination with a target pool.
Deployment Manager Infrastructure-as-Code
To create our Network Load Balancer programmatically we need the following code (YAML format):
Target Pool Creation
- name: "example-target-pool"
type: "compute.v1.targetPool"
properties:
region: "{{ properties['region'] }}"
# create the target pool with an empty list of
# instances - an instance group will be mapped
# to this target pool and will automatically
# manage the list of instances in the pool
instances: []
healthChecks:
- $(ref.example-health-check.selfLink)
You will notice that this target pool definition doesn’t actually include references to any instances. This is because we will be using an instance group instead, but an empty list of instances is still required. This is not particularly intuitive and we will expand on this below.
Note that the healthChecks property is a reference to another resource. The $() format is a standard Deployment Manager syntax for referencing other resources, and the selfLink property of the resource will return the full URL of the health check resource once it has been created, which is what the healthChecks property expects. Note also that the healthChecks property is actually an array of health check URLs (the hyphen syntax in YAML).
Health Check Creation
Next we can create the health check that is referenced by the above target pool:
- name: "example-health-check" type: "compute.v1.httpHealthCheck" properties: # port 80 is used by default if not specified explicitly port: 8080 # the default HTTP request path for the health check is # “/” so the following code is not actually required requestPath: “/” # the checkIntervalSec property defines how often # the health check performs its test, in seconds checkIntervalSec: 60
Forwarding Rule Creation
Finally we need to create the forwarding rule resource:
- name: "example-forwarding-rule"
type: "compute.v1.forwardingRule"
properties:
region: "{{ properties['region'] }}"
IPAddress: $(ref.example-staticip.address)
portRange: "80"
IPProtocol: TCP
target: $(ref.example-target-pool.selfLink)
Here we define the external IP address that will serve the traffic (in this case using a reference to an existing static IP address resource), the port and protocol for which we will serve requests, and the target pool that the traffic will be routed to.
Target Pools and Instance Groups
So far, so good. But assuming that the Compute Engine instances that will be serving traffic are in an instance group, how do we configure the above setup so that it knows to route traffic to whatever instances are currently active in that instance group? We could insert an static list of instances in the instances property of the target group resource, but obviously this will break as soon as an instance is terminated and replaced. This could happen because an instance fails and is automatically replaced, or due to an auto-scaling event, or a manual shutdown.
It would seem logical that instead of specifying the instances property of the target group as we do above:
- name: "example-target-pool" type: "compute.v1.targetPool" properties: instances: []
That we would instead reference an instance group. Maybe something like this:
- name: "example-target-pool" type: "compute.v1.targetPool" properties: instanceGroup: $(ref.example-instance-group.selfLink)
But this is NOT how it works.
In fact, the relationship is the reverse, and we have to tell our instance group about our target group, rather than the other way around. We link our the instance group to the target group, as a way of telling it “we are using this target group to serve your traffic, so if you add or remove instances, please update the target group to keep it in sync”. This is somewhat counter-intuitive and it’s not clear why it is necessary for the instance group to have any knowledge of the target group, but presumably Google had their reasons for implementing it this way around.
So we initially define our target group as containing an empty list of instances, as shown above. And then we create our instance group and link it back to the target group, as follows:
- name: "example-instance-group"
type: "compute.v1.instanceGroupManager"
properties:
zone: "{{ properties['zone'] }}"
# maintain a fixed number of two instances in the instance group
targetSize: 2
baseInstanceName: "example-instance"
instanceTemplate: $(ref.example-instance-template.selfLink)
# provide a link back to our target pool, so that the
# instance group can keep the target pool's list of
# instances in sync with the current active instances
# in the instance group
targetPools:
- $(ref.example-targetPool.selfLink)
Once all these resources have been created by Deployment Manager, the instance group will launch the required number of new instances (two in this example), and then notify the target pool of these instances. And then the forwarding rule will refer all incoming traffic to the target pool, which in turn will be able to route traffic to one of the currently active instances.
The following diagram shows the overall architecture:
Summary
GCP has a slightly more granular approach to structuring load balancing resources than you might be used to if coming from AWS Elastic Load Balancer and AWS Auto Scaling Groups, but otherwise works in a very similar way.
In a future article we will explore global HTTP(S) load balancing on GCP and the use of Internal Load Balancing for the balancing of internal backend services.
Footnote
We mentioned above that sometimes the Deployment Manager and related GCP online documentation can be quite difficult to translate into a working solution. If you are struggling to find the information you need in the online documentation, be sure to check the help content that is built into the gcloud command line interface. This often has additional valuable documentation, for example:
$ gcloud compute instance-groups managed set-target-pools --help NAME gcloud compute instance-groups managed set-target-pools - set target pools of managed instance group SYNOPSIS gcloud compute instance-groups managed set-target-pools NAME --target-pools=[TARGET_POOL,...] [--region=REGION | --zone=ZONE] [GLOBAL-FLAG ...] DESCRIPTION gcloud compute instance-groups managed set-target-pools sets the target pools for an existing managed instance group. Instances that are part of the managed instance group will be added to the target pool automatically. Setting a new target pool won't apply to existing instances in the group unless they are recreated using the recreate-instances command. But any new instances created in the managed instance group will be added to all of the provided target pools for load balancing purposes. ...continues...
The Supported Resource Types documentation is also a useful reference: